
这是 Prompt 提示工程系列的第五篇:
- Prompt 工程指南(一)—— 先导介绍篇
- Prompt 工程指南(二)—— 基础入门篇
- Prompt 工程指南(三)—— 高级技术篇之零样本与少样本提示
- Prompt 工程指南(四)—— 高级技术篇之思维链、自洽性与生成知识提示
- Prompt 工程指南(五)—— 高级技术篇之最前沿的提示技术研究成果
前面两篇介绍的提示技术已经可以在 ChatGPT 中体验,今天这篇介绍的则是提示工程中的最新研究成果,都是 2022 年 10 月之后发布的,甚至是一两个月之前发布的,所以暂时还不能在 ChatGPT 中进行演示,不过作为大语言模型(LLMs)最前沿研究,你可以关注以窥探未来的技术进展和方向。
学院君也会持续关注 ChatGPT 最新动态,然后补上对应的演示示例,请关注极客书房学习应用这些最新提示技术。
自动提示
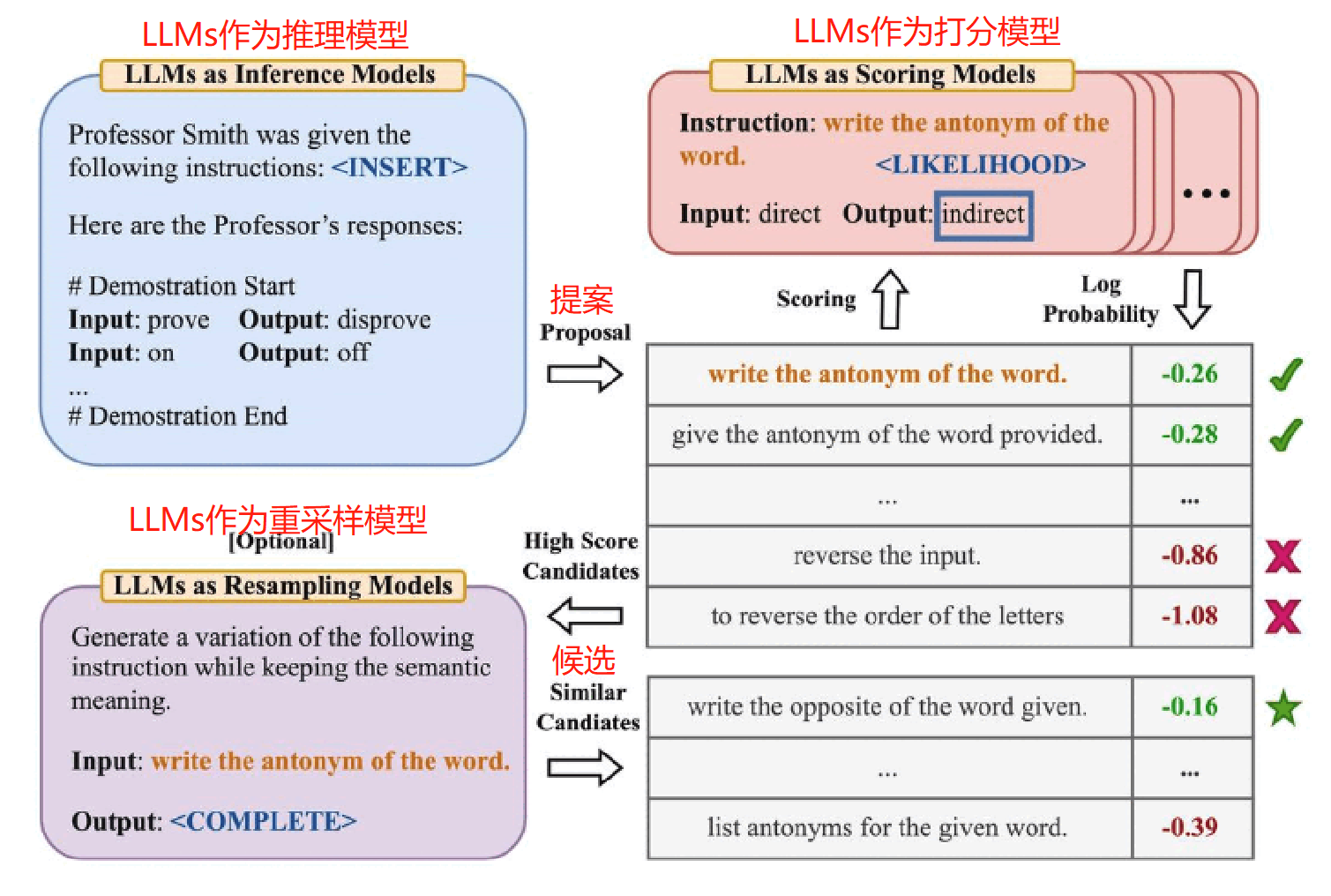
周等人 2022 年提出了一种自动提示工程师(Automatic Prompt Engineer,APE)框架,用于自动生成和选择指令。指令生成问题被构建为自然语言合成问题,并被视为一个利用大型语言模型(LLMs)生成和搜索候选解决方案的黑盒优化问题。
研究表明,大型语言模型(LLMs)在生成指令和提示方面表现出了与人类相当的能力,这种能力源于它们训练时学习的大量自然语言文本,因此它们可以生成类似于人类编写的指令和提示,这些指令和提示可以用于各种自然语言处理任务。
值得注意的是,对于某些任务,选择正确的提示是非常关键的。因此,研究人员提出了自动提示工程师(APE),它是一种自动选择提示和指令的方法,灵感来自于人类提示工程师的方法和经典的程序合成技术。
整个过程如下:
- 首先,基于“输入-输出对”形式的小集合,使用 LLMs 作为推理模型生成候选指令,如上图左上角所示,使用 LLMs 作为推理模型来填充空白,此算法涉及到搜索推理模型所提出的候选指令。
- 其次,通过为想要控制的 LLMs 下的每条指令计算一个分数(评分函数)来指导搜索过程(右上角 LLMs 作为打分模型,根据计算出的评估分数选择最合适的指令)。
- 最后,提出一种迭代蒙特卡洛搜索方法,LLMs 作为重采样模型通过提出语义相似的指令变体来改进最佳候选指令。

总之,该算法要求大语言模型根据示例生成一组候选指令集,然后再评估其中哪些更有效。即自动地为通过输出示例指定的任务生成指令:通过直接推理或基于语义相似性的递归过程生成几个候选指令,用目标模型执行它们,并根据计算出的评估分数选择最合适的指令。
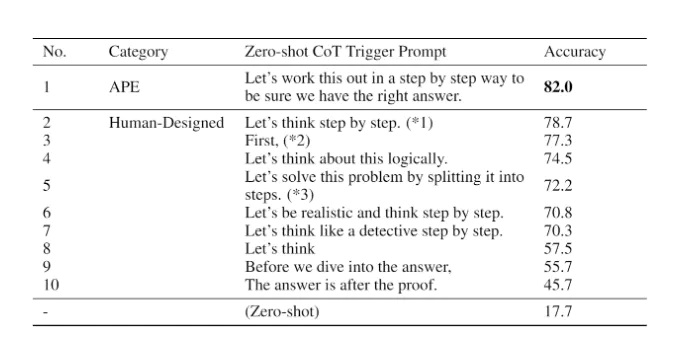
APE 发现了一个比人类工程师设计的”Let’s think step by step”提示(小岛等人2022年发表)更好的零样本 CoT 提示。提示 “Let’s work this out it a step by step to be sure we have the right answer.” 引发了思维链推理,并提高了在 MultiArith 和 GSM8K 基准测试上的性能:
这篇论文涉及到与提示工程相关的一个重要话题 —— 即自动优化提示的想法。虽然我们在本指南中没有深入探讨这个话题,但如果你对这个话题感兴趣,以下是一些关键论文:
- AutoPrompt —— 提出了一种基于梯度引导搜索来自动创建多种任务提示的方法。
- Prefix Tuning —— 一种轻量级的微调替代方法,为自然语言生成(NLG)任务添加一个可训练的连续前缀。
- Prompt Tuning —— 提出了一种通过反向传播学习软提示的机制。
主动提示
思维链提示依赖于一组固定的人工注释范例,这样做的问题是,这些范例可能不是不同任务最有效的示例。为了解决这个问题,刁等人 2023 年提出了一种名为主动提示(Active-Prompt)的新提示方法,以使大语言模型(LLMs)适应不同的任务特定示例提示(用人工设计的 CoT 推理进行注释)。
主动提示是一种自动提示方法,可在不需要手动编写提示的情况下,激发 LLMs 中的思维链推理能力。这种方法能够提高 LLMs 的推理能力,并将其用于大量应用程序中。
在当前自然语言处理领域,LLMs 已成为主流模型之一,它具有处理自然语言任务的强大能力,包括问答、文本补全、翻译等任务。通过使用基于思维链的主动提示方法,可以进一步提高 LLMs 的准确性和能力。
以下是该方法的示意图:
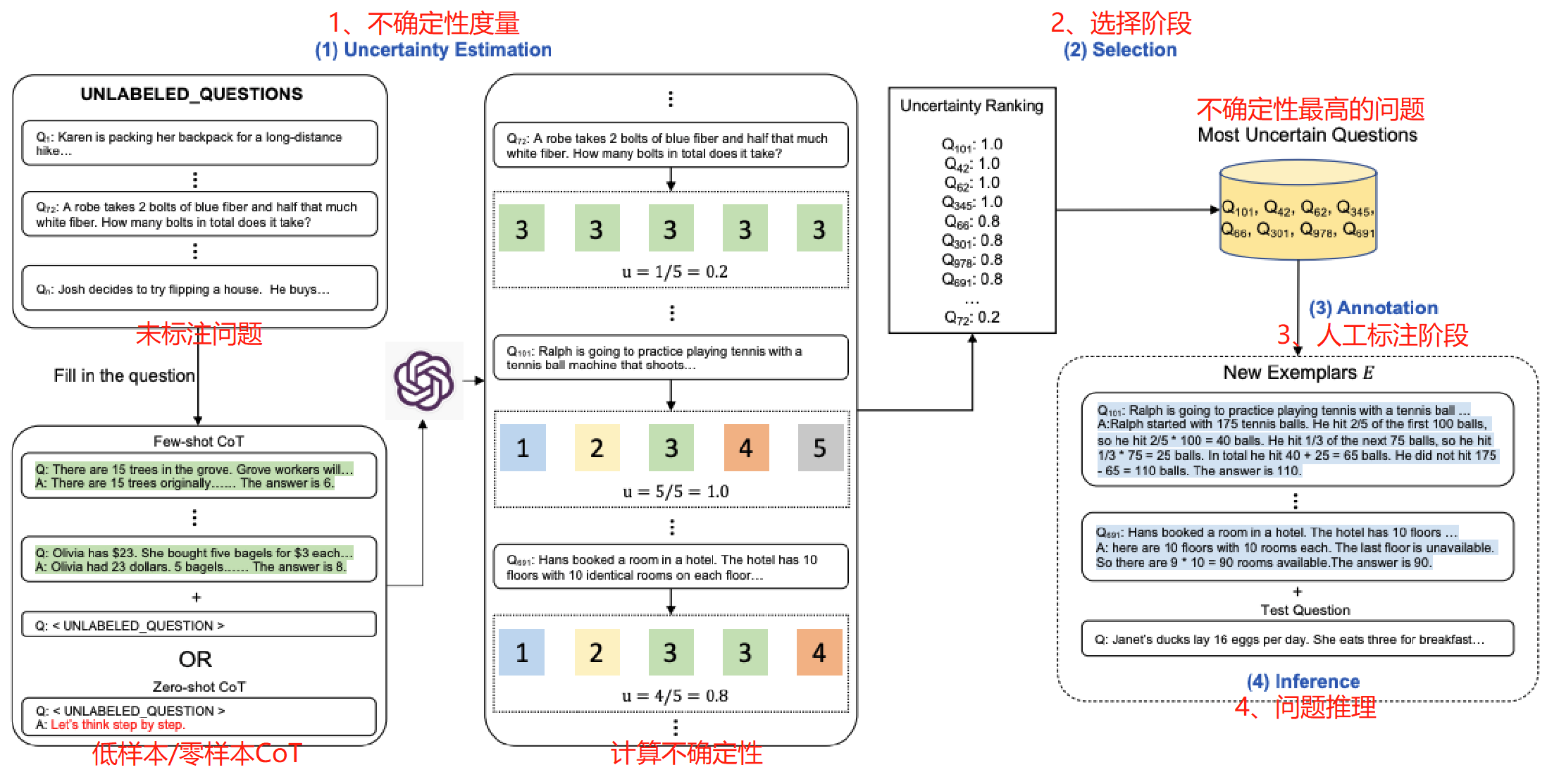
整体上参考主动学习的框架,即模型预测->不确定性指标选择->人工标注->继续迭代分成四个阶段:
- (1)度量阶段:对于未标注问题基于低样本思维链(Flew-shot CoT)或者零样本思维链(Zero-shot CoT)方式,LLMs 对训练集中每个问题进行重复 k 次采样输出,对产生的答案计算不确定性指标;
- (2)选择阶段:选择不确定性指标最高的问题用于后续标注;
- (3)标注阶段:人工参与对选择的问题进行标注;
- (4)推理阶段:使用最新的标注示例做问题推理。
定向刺激提示
李等人 2023 年提出了一种新的提示技巧 —— 定向刺激,以更好地引导大语言模型(LLMs)生成所需的摘要:
- 该框架使用一个策略语言模型来生成离散Token,作为指导大型语言模型的方向性刺激;
- 生成的刺激与原始输入相结合,并输入到大型语言模型中,以引导其向特定目标生成;
- 策略语言模型可以通过监督学习和强化学习进行训练,以探索方向性刺激,使大型语言模型与人工偏好更好地结合起来;
- 该框架适用于各种语言模型和任务,只需收集少量的训练数据就能显著提高性能。
通过定向刺激提示指导大语言模型是一种新的框架,它使用可调节的语言模型来为黑匣子模型提供指导,用少量训练数据集合即可提高性能。在这个新的框架中,模型可以根据提示中的关键字和语法结构进行指导,这些提示可以是一些例子,也可以是几行说明。通过这些提示,模型可以生成出所期望的摘要和结论。
这种方法可以应用于各种自然语言处理任务,包括机器翻译、摘要生成和对话生成等。此外,由于可以对提示进行微调,因此该框架可以适应各种不同的应用场景。
下面的图表展示了定向刺激提示与标准提示之间的比较,策略语言模型可以很小,并优化以生成引导黑盒冻结大语言模型的提示:

ReAct
姚等人 2022 年介绍了一个新框架 —— ReAct(Reason and Act),顾名思义,这是一个将推理和行动相结合的新兴框架。在这个框架中,大语言模型被用来以交错的方式生成推理轨迹和任务特定的动作。生成推理轨迹使模型能够引导、跟踪和更新动作计划,甚至处理异常情况。动作步骤允许与外部资源(如知识库或环境)进行交互并从中收集信息。
ReAct 框架可以使 LLM 与外部工具互动,检索更多的信息,从而得到更可靠、符合事实的回答:

ReAct 模式将是 ChatGPT 的一个里程碑式的进步,它可以让 ChatGPT 从单机模式变成了联机模式,从单纯的回答问题变成了可以使用工具和其他对象交互的模型。
多模态思维链提示
张等人 2023 年提出了一种多模态思维链提示方法,旨在将语言(文本)和视觉(图像)模态相结合。传统的思维链主要关注语言模态,相比之下,多模态思维链将文本和视觉融入到一个两阶段的框架中:
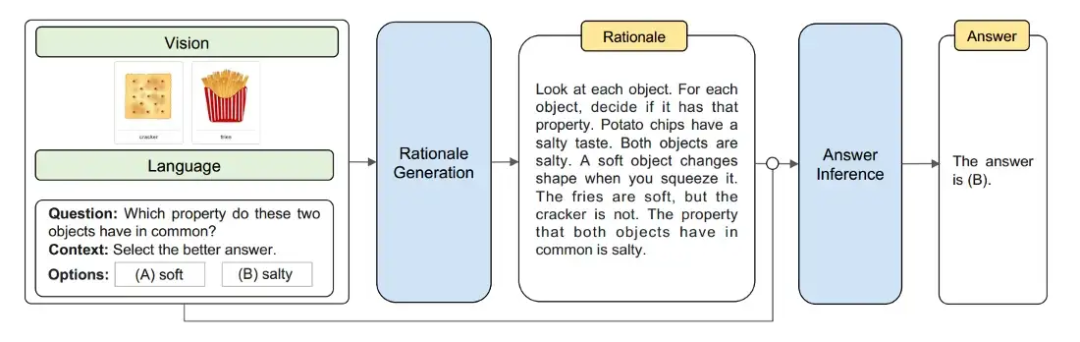
- 第一阶段基于多模态信息(文本+视觉)生成理由。
- 接下来是第二阶段 —— 利用上一步生成的信息丰富的理由进行答案推理。
多模态CoT模型(1B)在 ScienceQA 基准测试上的表现优于 GPT-3.5:
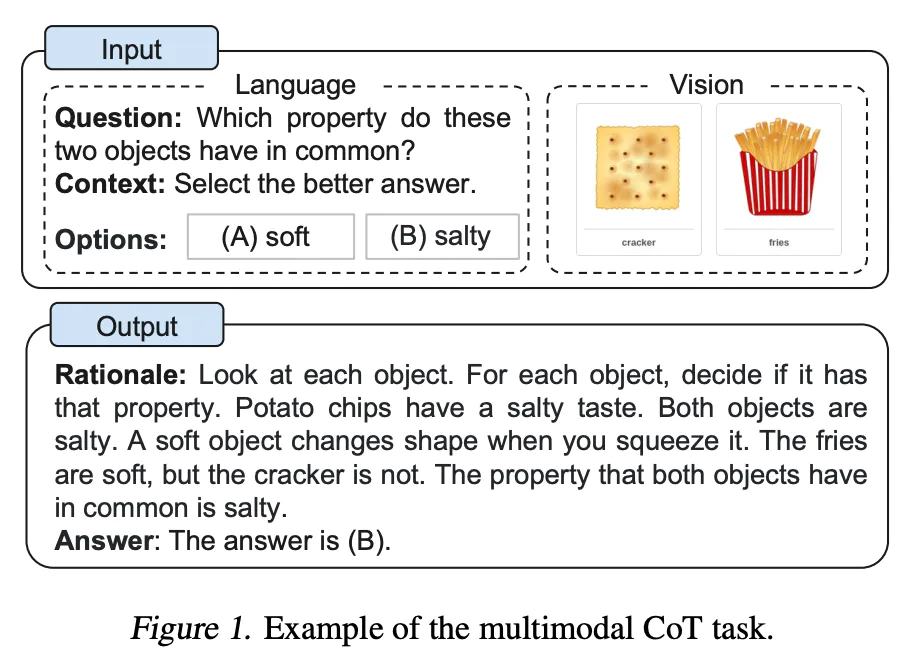
这个课题是一个新的研究方向,相关研究成果还不太多。不过,这个课题提出的框架有望为语言模型的推理能力提供新的思路和方法,这可能会对自然语言处理、计算机视觉、人工智能等领域的发展产生一定的推动作用。
GraphPrompt(图提示)
刘等人 2023 年介绍了 GraphPrompt,这是一种新的图提示框架,用于提高下游任务的性能。
GraphPrompt 是一种用于图神经网络的新型预训练和提示框架,该框架不仅将预训练和下游任务统一到一个通用的任务模板中, 还采用可学习提示来帮助预测。该框架提供了一种新型的预训练方法,使得预训练和下游任务可以同时进行,从而提高了图神经网络的效果。
GraphPrompt 不需要额外的语言表达来提示,因为它采用了一种新的可学习提示方法,这种方法将任务分解为子任务,并使用提示来指导子任务的完成,而不是简单地使用传统的训练方法。同时,该框架可以有效地处理图中的各种任务,如节点分类、图分类、图生成等。
GraphPrompt 框架提供了代码和数据集,以方便研究人员使用。该框架为研究人员提供了一个新的研究方向,即如何利用可学习的提示来提高图神经网络的性能。
欢迎加入免费的 AI&ChatGPT 研习社与大家一起讨论 AI&ChatGPT 的最新动态,免费领取最新 AI 相关的学习资源:

你还可以微信扫码关注我的微信公众号获取极客书房最新动态:





