
这是 Prompt 提示工程系列的第三篇:
- Prompt 工程指南(一)—— 先导介绍篇
- Prompt 工程指南(二)—— 基础入门篇
- Prompt 工程指南(三)—— 高级技术篇之零样本与少样本提示
到目前为止,显而易见的是,改进提示有助于在不同任务上获得更好的结果。这就是提示工程背后的理念和目标。
虽然上篇教程介绍的基本示例已经很有趣,但在接下来的几篇教程中,我们将介绍更高级的 Prompt 提示工程技巧,使我们能够完成更复杂且有趣的任务。有意思的是,你可以看到这些技巧背后的算法论文绝大部分都是华人领衔发表的。
我们先从覆盖日常绝大部分提示场景的零样本和少样本提示开始。
零样本提示
目前的大语言模型(LLMs)通过大量的数据训练和指令调整,能够在零样本情况下完成任务。在前面的教程中,我们已经尝试了一些零样本示例。以下是我们使用过的一个示例:
提示:
将文本分类为 neutral、negative 或 positive。
文本:我认为度假还可以。
情感:
输出:

请注意,在上面的提示中,我们没有为模型提供任何示例 —— 这就是零样本能力的体现。
指令调整已经显示出可以改善零样本学习。
微调(Finetuned)预训练大语言模型可以达到零样本学习的效果。所谓零样本学习,是指在没有见过某些特定任务的数据的情况下,模型可以通过利用先前学习到的知识来完成该任务。
这一技术的基本思想是,将一个预先训练好的通用大语言模型(例如GPT)进行微调,使其适应于特定的任务集。然后,该模型可以通过输入任务的自然语言描述,来学习该任务。最终,经过适当的微调,该模型可以在未见过的任务上实现很好的性能。
这里其实背后应用到了机器学习的能力,在大语言模型之前需要非常专业的机器学习知识和技能才能完成这一功能,而现在,只需要简单通过文本提示即可完成,所以大语言模型的一大贡献就是将机器学习这一金字塔尖的技术门槛拉低到普通人也能训练。
这一技术的优点在于可以大大减少对大规模训练数据的需求,同时还可以提高模型的泛化能力。另外,由于可以通过自然语言来描述任务,这种技术也更具有可解释性和可操作性。
更多细节参考魏等人于2022年发表的Finetuned Language Models are Zero-Shot Learners这篇论文。
指令调整实质上是将模型微调到通过指令描述的数据集上。此外,RLHF(reinforcement learning from human feedback:从人类反馈中进行强化学习)已经被采用来扩展指令调整,以便模型与人类偏好更好地对齐,这种最新发展推动了像 ChatGPT 这样的模型。
RLHF 是强化学习的一种形式,它利用人类反馈直接优化语言模型。在 RLHF 中,代理通过与环境的交互学习策略。该方法的一个重要组成部分是从人类反馈中推断出奖励函数。一旦获得了奖励函数,下一步就是学习最大化奖励的策略。
RLHF 的主要目的是通过从人类反馈中学习最优决策来改善语言模型。这个方法有许多应用,如自然语言生成、对话系统、语音识别等。例如,在对话系统中,RLHF 可以从用户反馈中学习生成最佳回复。
需要注意的是,使用 RLHF 需要大量的人类反馈数据,因此对于一些领域,例如法律或医疗保健等需要专业知识的领域,收集反馈可能会更具挑战性。
我们将在接下来的教程中讨论所有这些方法。
当零样本不起作用时,建议在提示中提供演示示例,这会将零样本提示转化为少样本提示。接下来,我们将演示少样本提示。
零样本提示是新手使用 ChatGPT 最常规的提示方式了,但它也是后续其他所有高级提示技术的基础。
少样本提示
虽然大语言模型表现出卓越的零样本能力,但在使用零样本设置时,在更复杂的任务上仍然表现不佳。少样本提示可以通过在提示中提供演示示例来启用上下文学习,以引导模型更好地执行任务,以演示示例作为条件,用于后续我们希望模型生成响应的示例。
让我们通过 Brown 等人 2020 论文中提供的一个示例演示少样本提示。
大语言模型具备强大的少样本学习能力,能够在很少的示例中完成各种自然语言处理任务。大语言模型的可扩展性是关键因素,它能够有效地学习到各种不同的自然语言处理任务,并取得出色的表现。少样本技术的主要优势在于,大大降低了对特定任务数据的需求,并减少了过度学习的风险。
大语言模型的强大表现对于自然语言处理领域具有很大的推动作用。其能够在不同的任务上取得出色的表现,而且只需要很少的训练数据。这对于解决自然语言处理中的各种问题非常有帮助。但是,也需要注意到语言模型存在一些限制和局限性,如偏见、稀有单词和不合理的生成等问题。因此,我们需要在使用语言模型时保持谨慎并注意它们的局限性。
更多细节参考 Language Models are Few-Shot Learners 这篇论文。
在这个例子中,要处理的任务是在句子中正确使用一个新词。
提示:
“whatpu” 是一种生长在坦桑尼亚的小型毛茸茸的动物。使用 whatpu 这个词的一个例子是:
我们在非洲旅行,看到了这些非常可爱的 whatpu。
“farduddle” 的意思是快速跳跃。使用 farduddle 这个词的一个例子是:
输出:

我们可以观察到,通过仅提供一个例子(即1-shot),模型已经学会了如何执行任务。对于更困难的任务,我们可以尝试增加演示次数(例如3-shot,5-shot,10-shot等)。
根据 Min 等人 2022 年的发现,以下是在进行少样本提示时关于演示示例的一些其他提示:
这个发现指的是通过大语言模型 (LLMs) 的情境学习展示了一种新的学习方式,即只需在少量的输入-标签对(演示)上进行推理即可执行新任务。通过对演示的重新思考,可以更好地理解情境学习的工作原理,同时也引发了对于可以通过情境学习学到多少的新问题。该研究提供了新的方式来理解情境学习的工作方式。此外,研究结果还包括原创的实现。
- 标签范围和演示指定的输入文本的分布都很重要(无论单个输入的标签是否正确)
- 即使只使用随机标签,通过格式也会对结果起关键作用,这比根本不使用标签好得多
- 额外的研究结果显示,从真实标签分布中选择随机标签(而不是均匀分布)也有帮助
让我们尝试几个例子。
首先,让我们尝试一个带有随机标签的例子(这意味着将负面和正面标签随机分配给输入):
提示:
这太棒了! // Negative
这很糟糕! // Positive
哇,那部电影很酷! // Positive
这是一个多么可怕的节目! //
输出:

即使标签已经被随机化,我们仍然得到了正确的答案。请注意,我们也保持了格式,这也有助于结果。事实上,通过进一步的实验,我们发现我们正在尝试的新的 GPT 模型甚至对随机格式变得更加稳健。例如:
提示:
Positive 这太棒了!
这很糟糕!Negative
哇,那部电影真的很棒!
Positive
真是一场糟糕的表演!--
输出:
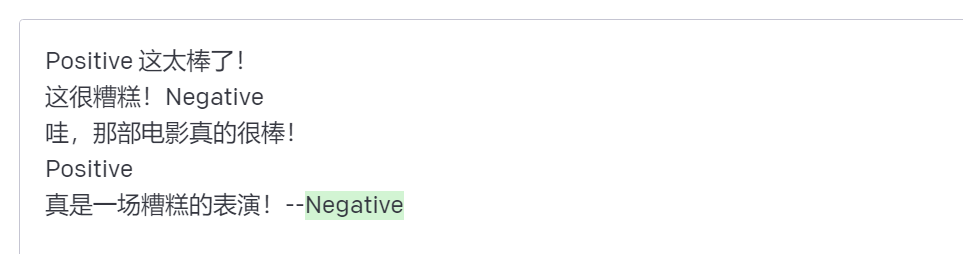
上面的格式保持一致,但模型仍然预测了正确的标签。我们需要进行更彻底的分析,以确认其是否适用于不同和更复杂的任务,包括提示的不同变化。
少样本提示的不足
少样本提示技术对许多任务都有效,但仍不是完美的技术,特别是在处理更复杂的推理任务时。下面我们用一个例子来说明为什么会这样。在上一篇教程的末尾我们提供了下面这个任务:
这组数中的奇数相加得到一个偶数:15, 32, 5, 13, 82, 7, 1。
A:
如果我们再试一次,模型会输出以下内容:

这不是正确的答案,这不仅突显了这些系统的局限性,也说明需要更先进的提示工程。
让我们试着添加一些示例,看看少样本提示是否可以改善结果。
提示:
这个组中的奇数加起来是一个偶数:4、8、9、15、12、2、1。
A:答案为不是。
这个组中的奇数加起来是一个偶数:17、10、19、4、8、12、24。
A:答案为是。
这个组中的奇数加起来是一个偶数:16、11、14、4、8、13、24。
A:答案为是。
这个组中的奇数加起来是一个偶数:17、9、10、12、13、4、2。
A:答案为不是。
这个组中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:
输出:
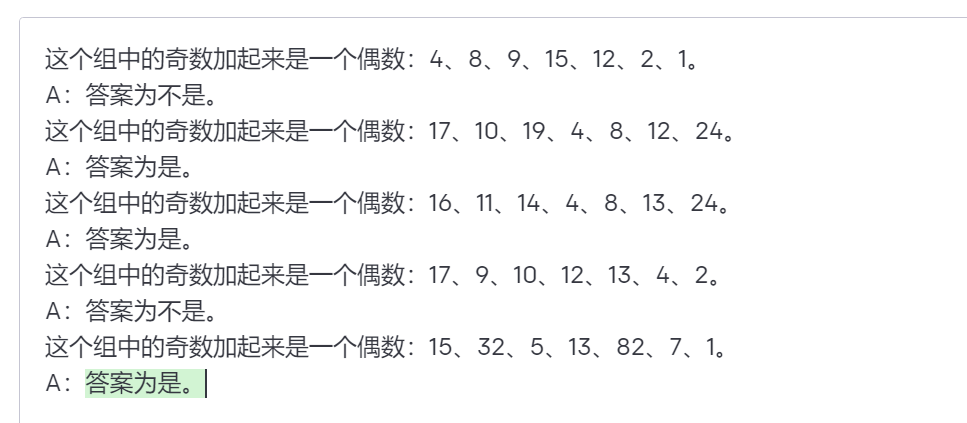
这并没有起作用。似乎少样本提示不足以获得这种类型推理问题的可靠答案。上面的示例提供了任务的基本信息,如果你仔细观察,我们介绍的任务类型涉及到更多的推理步骤。换句话说,如果我们将问题分解成多个步骤并向模型演示,可能会有所帮助。因此,最近思维链提示(CoT)流行起来,用于解决更复杂的算术、常识和符号推理任务。
总的来说,提供示例对于解决某些任务是有用的。当零样本提示和少样本提示都不够时,可能意味着模型的学习能力不足以在任务中表现良好。从这里开始,建议考虑微调你的模型或尝试更先进的提示技术。接下来,我们将讨论一种流行的提示技术 —— 思维链提示,该技术已经受到了广泛的关注。
最后,欢迎大家加入免费的 AI&ChatGPT 研习社与大家一起讨论 AI&ChatGPT 的最新动态,免费领取最新 AI 相关的学习资源:

你还可以微信扫码关注我的微信公众号获取极客书房最新动态:





