Google 文档翻译的问题
最近两周给极客智坊新增了 PDF 文档翻译和批量网页翻译的能力,PDF 文档翻译要先支持顺序提取所有文字、链接、图片、表格,这一块还是挺复杂的,因为 PDF 本身是一个侧重表现层显示而非结构标准化的文档格式,即便是强如 Google/DeepL 的 PDF 文档解析也有不尽如人意的地方,比如下面红框是 Google 翻译 https://arxiv.org/pdf/2310.15987.pdf 这篇论文的时候提取的图片:
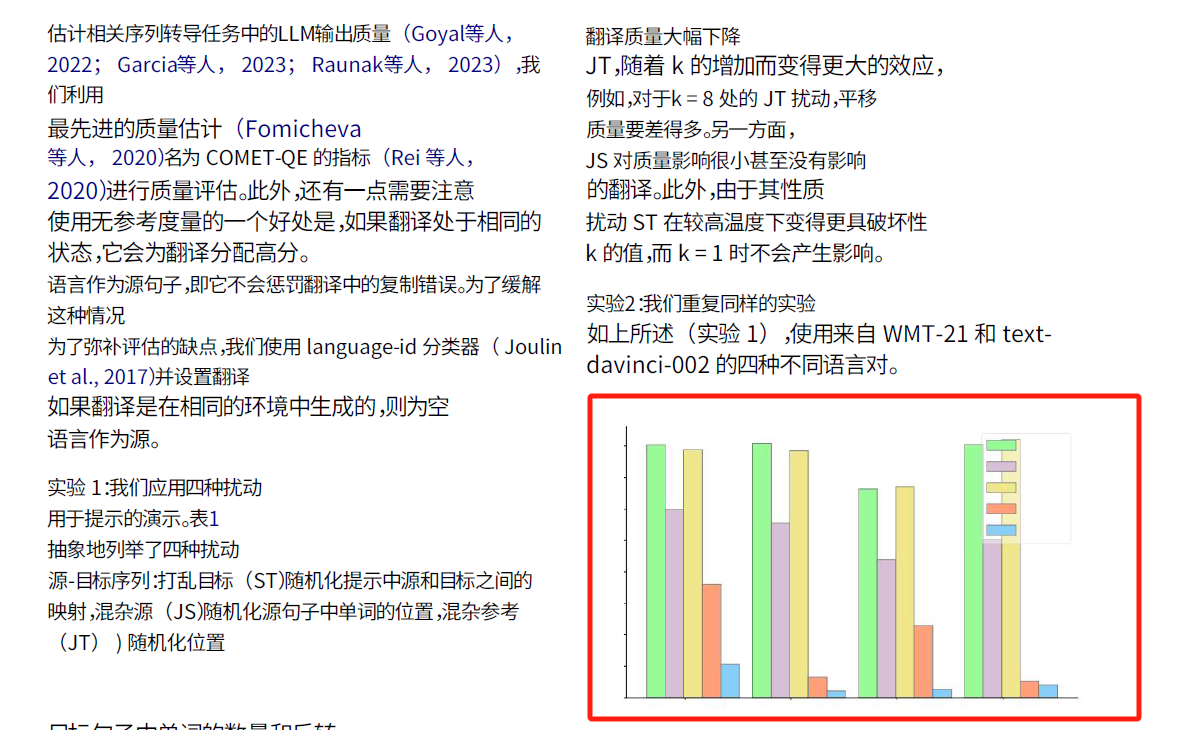
而原图实际上是这样:
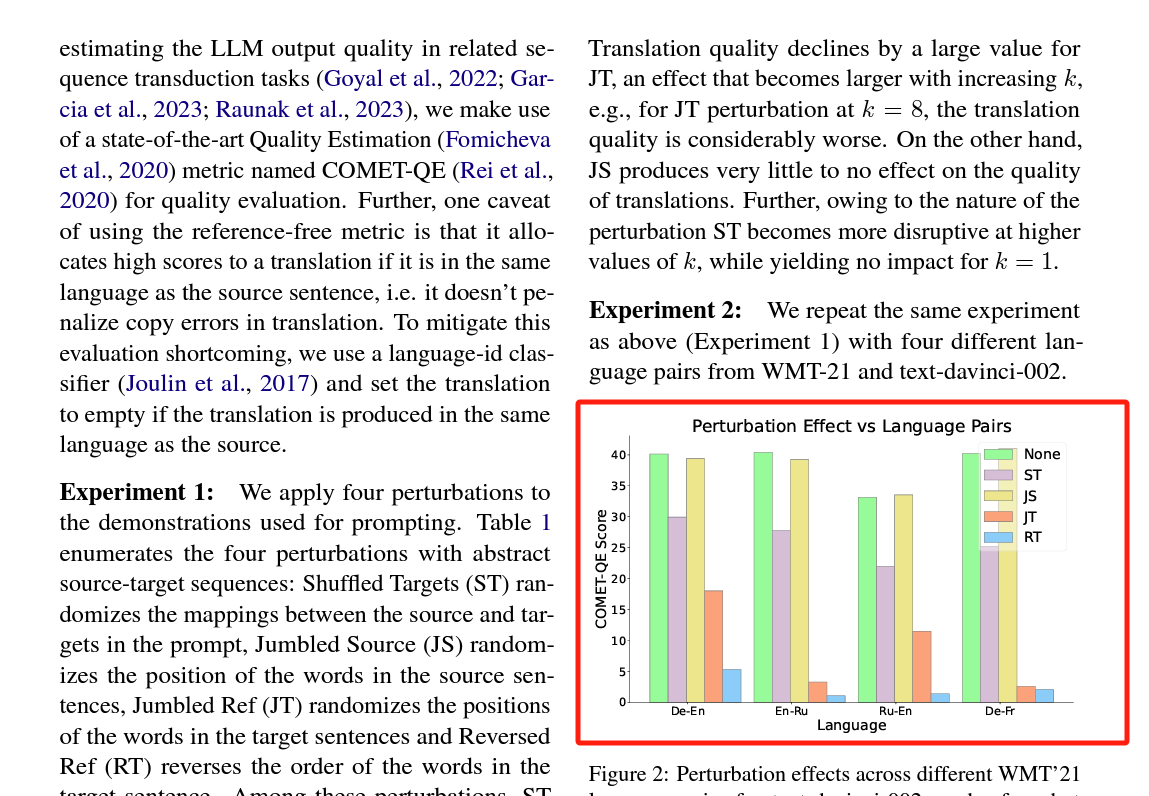
可以看到坐标轴上的参数和图示说明文字都弄丢/错位了,说明提取图片的时候还是有问题。
至于翻译质量,在非常有深度的行业内容翻译的时候,Google 翻译也并不准确,比如下面这个:
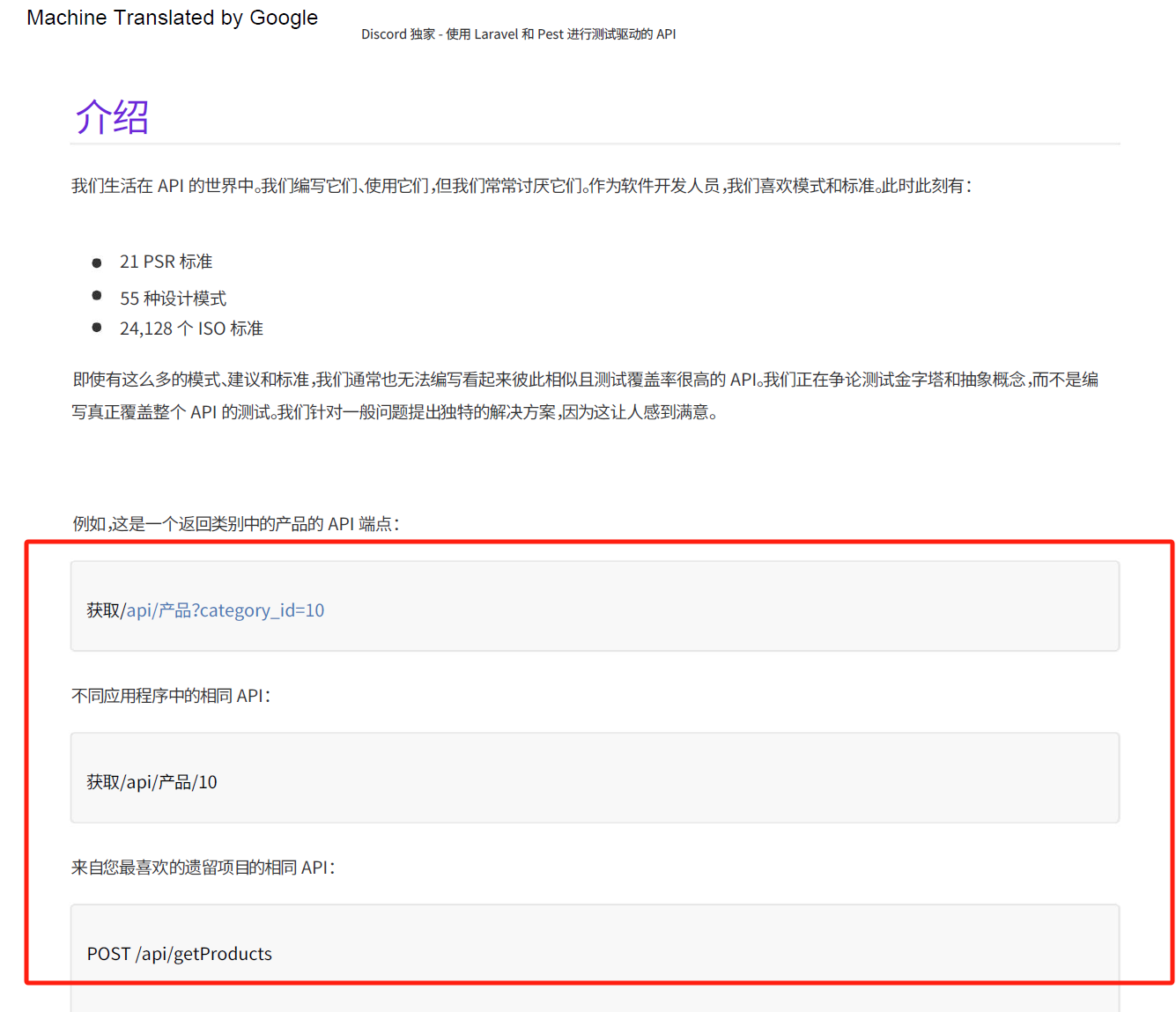
把代码都翻译了,这对于 IT 技术类的 PDF 文档来说,就非常不友好了。
所以,这里我需要选择更好的 PDF 文档提取技术然后通过 GPT 模型进行翻译,以解决信息完整性和翻译质量问题。尤其是 PDF 文档信息提取,耗费了非常多的时间和精力,不过终于还是解决了这个问题。
极客智坊 PDF 文档翻译
要翻译 PDF 文档,请进入极客翻译页面,点击顶部文档翻译Tab按钮,选择翻译用的AI模型和目标语言,然后点击上传按钮上传待翻译的PDF文件即可,我们以前面 Google 翻译的那篇 PDF 论文为例进行演示,上传成功后,可以在右侧区域看到如下提示:
点击后台任务即可进入后台任务列表看到这个翻译任务:
文档翻译时间不好预测,对于大文件来说可能非常耗时,已经不再适合通过聊天对话返回结果,所以这次功能升级提供了一个支持排队的后台任务系统统一处理极客智坊异步耗时任务。
如果任务执行失败,支持重试:

执行成功,则可以通过下载按钮下载翻译结果(也是PDF格式):

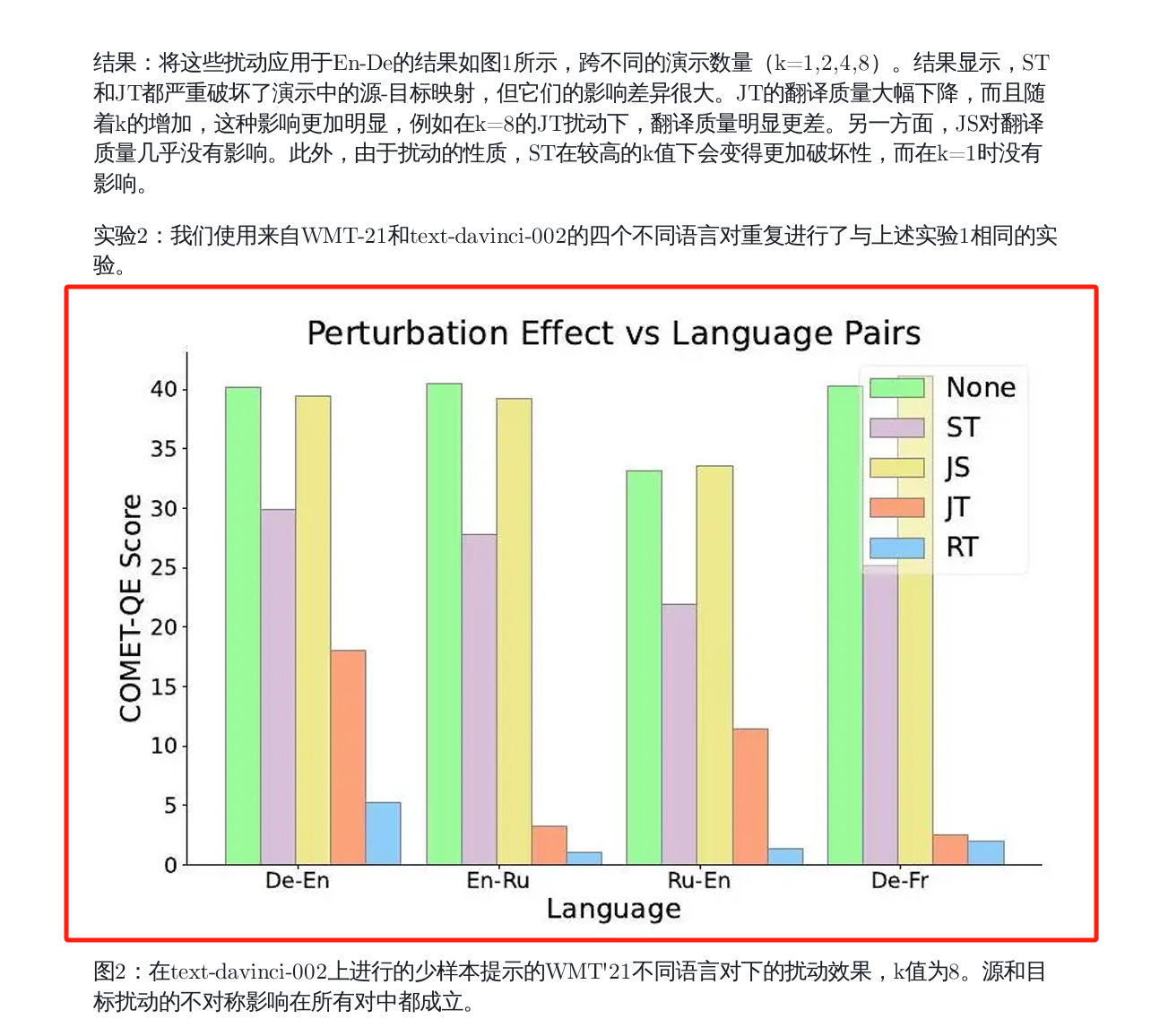
极客智坊会将两列布局变成一列垂直平铺展开,通过和前面 Google 对比可以看到,极客智坊的文档翻译完整保留了图片的整体性没有破坏。
至于翻译质量,GPT模型显然是优于Google翻译的,比如技术文档翻译,GPT可以识别代码/专业术语并进行保留而不做翻译:

极客智坊的 PDF 翻译服务不仅是论文翻译神器,几百页的图书翻译也不在话下:


另外,如果在网页翻译中提取网页内容失败(通常是网络、权限等问题导致),可以通过将网页另存为本地HTML,然后通过文档翻译上传HTML进行翻译实现“曲线救国”的目的。
极客智坊网页批量翻译
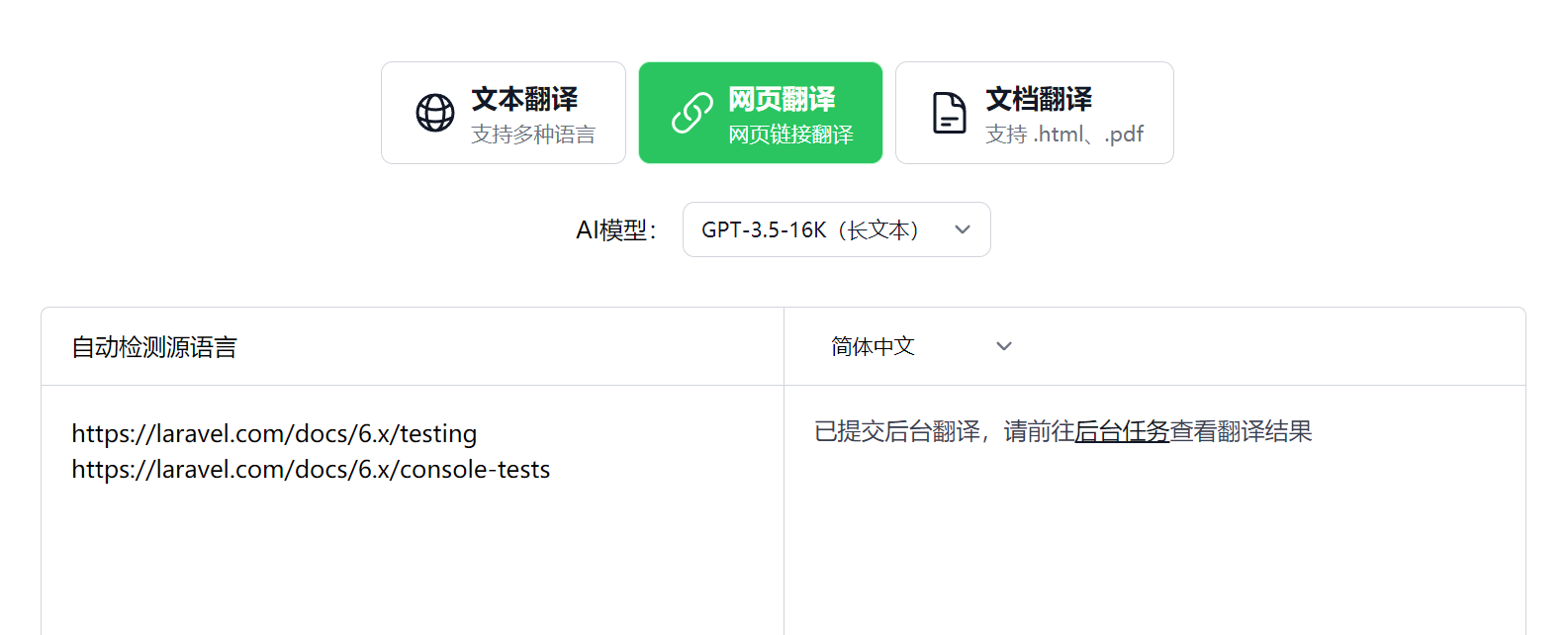
既然有了后台排队任务系统,那么实现网页批量翻译也就顺理成章了,你可以在网页翻译中一次性提交多个网页链接(通过回车分隔,一行一个):
然后点击翻译按钮,系统会自动将批量网页翻译提交到后台排队任务系统异步执行(单个网页链接保持原来的逻辑不变):
翻译成功后,点击下载按钮即可下载翻译结果:
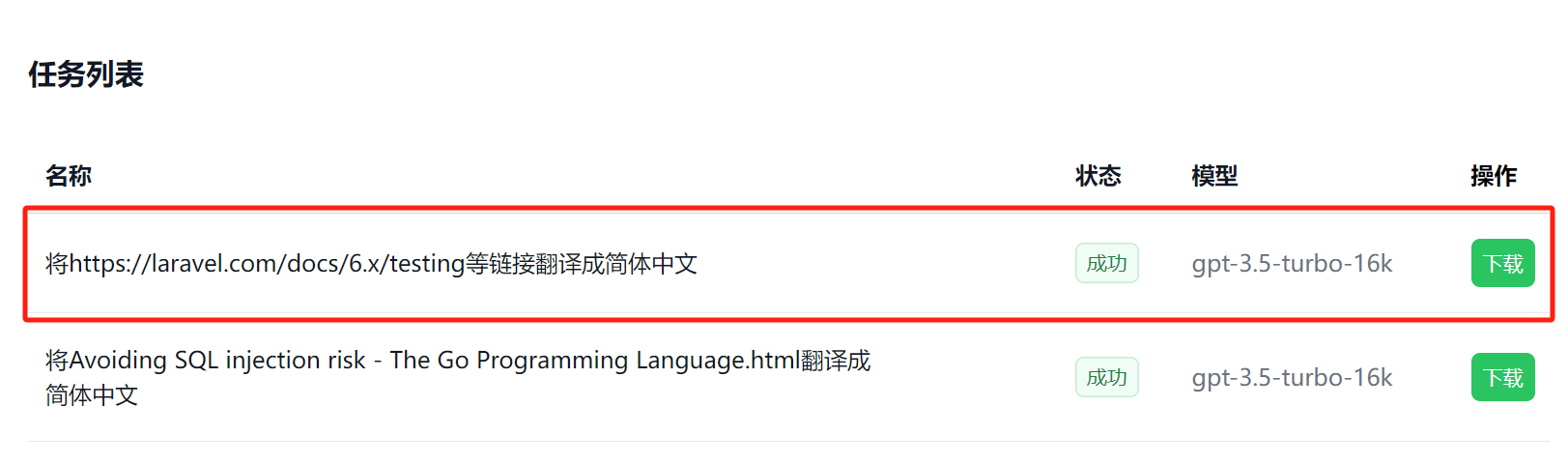
系统会将每个网页翻译结果保存到单独的 MD 文件中,文件名就是网页标题,然后打包成一个 zip 文件提供下载:

这对一些需要翻译某个主题系列文档的场景非常友好。
立即体验上述新功能特性:点击前往极客智坊文档翻译。